ASR : comment fonctionne aujourd’hui la reconnaissance automatique de la parole ?

L’ASR — pour Automatic Speech Recognition — désigne les technologies capables de transformer la parole en texte. En français, on parle aussi de SRAP, pour Système de Reconnaissance Automatique de la Parole. Longtemps associée à la simple dictée vocale, cette technologie couvre désormais bien plus large : transcription automatique, sous-titrage, recherche dans les contenus audio, accessibilité, traduction automatique et traitement multilingue.
Depuis notre précédent article publié en 2016, le secteur a profondément évolué. Les systèmes historiques reposaient sur des chaînes de traitement complexes, mais les progrès récents en IA neuronale, en deep learning et en modèles de langage ont permis d’améliorer considérablement la performance des solutions de speech to text.
Dans ce contexte, des outils comme Authôt, assistant métier de transcription permettent aujourd’hui d’exploiter pleinement le potentiel de la reconnaissance automatique de la parole dans des usages professionnels.
Qu’est-ce que l’ASR ou SRAP exactement ?
Un Système de Reconnaissance Automatique de la Parole SRAP permet de convertir un signal audio en texte. Cette transcription automatique peut être utilisée dans de nombreux contextes : réunions, interviews, conférences, sous-titrage ou documentation.
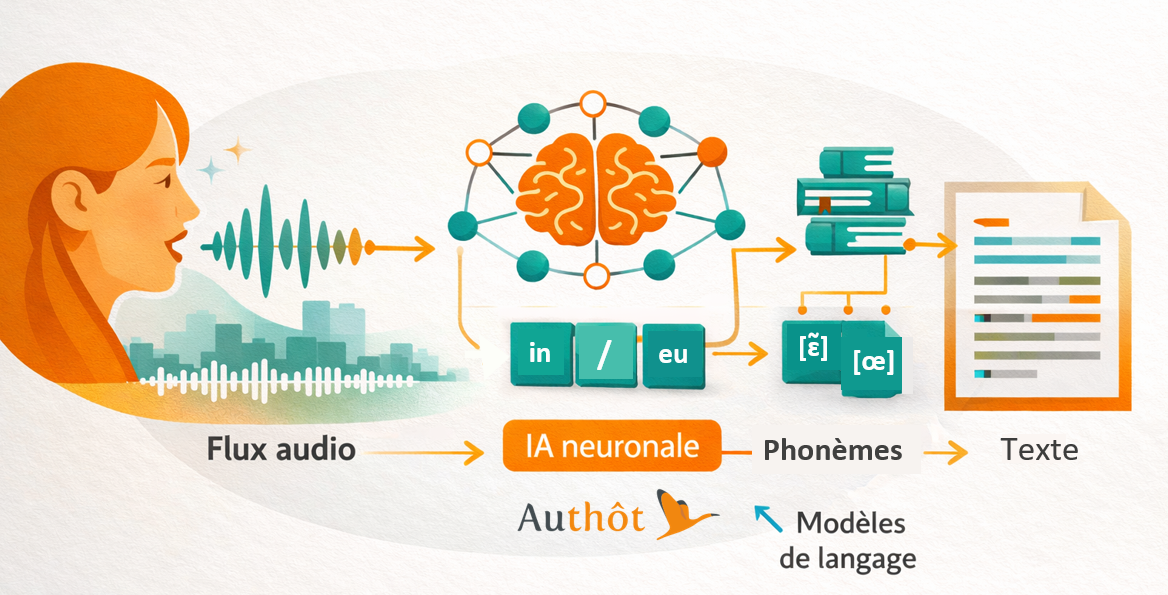
Contrairement à un humain, un système ASR fonctionne de manière probabiliste. Il analyse des sons, les associe à des phonèmes, puis reconstruit les mots les plus probables grâce à un modèle de langage.
Cette dimension est essentielle : une transcription automatique ne se limite pas à une conversion technique. Elle répond à des enjeux de communication, d’accessibilité et d’exploitation de l’information. Pour approfondir ce sujet, vous pouvez consulter notre article sur qu’est-ce que la transcription ou découvrir notre solution de transcription professionnelle.
L’ASR ou SRAP peut également être enrichi par d’autres fonctionnalités : identification des locuteurs, segmentation mono-locuteur ou multi-locuteurs, traduction automatique ou synthèse vocale.
Pourquoi l’ASR a autant progressé ces dernières années ?
Les progrès récents de l’ASR reposent sur plusieurs facteurs :
- l’augmentation des données disponibles ;
- la puissance de calcul ;
- les avancées en IA neuronale.
Les modèles récents permettent aujourd’hui d’améliorer :
- la gestion des accents ;
- la robustesse face au bruit ;
- les performances en contexte multilingue ;
- la compréhension des conversations naturelles.
Comme expliqué dans notre article sur le nouveau système de reconnaissance automatique de la parole basé sur Whisper, ces technologies ont fortement amélioré la qualité de la transcription automatique.
Elles permettent également des usages en temps réel, comme la transcription et traduction en direct, facilitant la communication dans des environnements internationaux.
Comment fonctionne une technologie de reconnaissance automatique de la parole ?
Une technologie de reconnaissance automatique de la parole repose sur plusieurs étapes :
- analyse du signal audio ;
- identification des phonèmes ;
- modélisation acoustique ;
- utilisation d’un modèle de langage ;
- génération du texte final.
Même avec les modèles modernes, les principes restent similaires : transformer un signal sonore en texte cohérent.
La gestion des locuteurs est également un point clé. Dans les contextes complexes, il est essentiel de distinguer les intervenants.
Vous pouvez en savoir plus dans notre article sur le mono-locuteur et multi-locuteurs.
Taux d’erreur mot : comment évaluer une transcription automatique ?
Le taux d’erreur mot (Word Error Rate) est l’indicateur principal pour évaluer la qualité d’un système de speech to text.
Il prend en compte :
- les substitutions ;
- les suppressions ;
- les insertions.
Un faible taux signifie une meilleure qualité de transcription automatique, mais il doit toujours être analysé en fonction du contexte : qualité audio, vocabulaire métier, nombre de locuteurs.
La compréhension des phonèmes joue ici un rôle essentiel. Une mauvaise interprétation peut entraîner des erreurs en cascade.
Quels sont les cas d’usage de l’ASR aujourd’hui ?
Les applications de l’ASR sont nombreuses :
- transcription automatique de réunions, interviews, conférences ;
- sous-titrage pour l’accessibilité ;
- dictée vocale ;
- traduction automatique ;
- analyse de contenus audio.
Ces usages répondent à des enjeux d’accessibilité et d’inclusion. Transformer la parole en texte permet de rendre l’information plus accessible et exploitable.
L’ASR est également complémentaire d’autres technologies comme la synthèse vocale. Pour approfondir ce sujet, vous pouvez consulter notre article sur le text to speech.
L’ASR aujourd’hui : une technologie mature mais dépendante du contexte
La reconnaissance automatique de la parole a connu des avancées majeures. Cependant, elle n’est pas universelle : ses performances dépendent du contexte, des données et des usages.
La qualité d’un Système de Reconnaissance Automatique de la Parole (SRAP) varie selon :
- la langue ;
- l’environnement sonore ;
- le vocabulaire ;
- le nombre de locuteurs ;
- le niveau d’exigence attendu.
C’est pourquoi l’intégration dans des outils adaptés reste essentielle. Des solutions comme Authôt permettent d’exploiter pleinement le potentiel de la transcription automatique dans des contextes professionnels.
Comprendre l’ASR, ses mécanismes et ses limites permet ainsi d’en faire un véritable levier de performance, de productivité et d’accessibilité.